エクセルで保存した情報を簡単に処理して、その結果を社内のデータベースに転記する作業がある。そのデータベースのインターフェースはブラウザになっていて、恐ろしいことに(?)そのブラウザに表示される100~300くらいある(場合によってはもっとたくさんある)テキストボックス(inputで作られている)には、一括でエクセルのデータをコピペすることができないようになっている。なので、基本的には、100~300ある(場合によってはそれ以上の)テキストボックスには、エクセルの計算結果を一つずつコピペ、または、一つずつ手入力することが求められる設計となっている。
誰にとっても明白なように、一つずつコピペをしたり手入力するのは時間の浪費であるし、またミスの温床になりかねない。なので、ブラウザに入力するための別のエクセルを作成して、そこに一度計算結果をコピペして、そこからそのエクセルのVBAでブラウザに情報を渡すようにしている。
情報の処理・保存用のエクセル→→(コピーandペースト)→→ブラウザに情報を渡すVBAエクセル→→(VBA)→→ブラウザに入力完了
このVBAエクセルのおかげで作業はずいぶん楽になったのだけれども、やはりまだ辛い。結局、初めのエクセルから次のエクセルへコピペする作業は、文字通り「作業のための作業」であるからだ。ということで、少しでもこの作業を有意義なもの(?)にしようと考えて、少し調べてみたら、Python の pyperclip というライブラリーを使うとなんとかなりそうだと判明。pyperclip はコピーした文字列を取得できてしまう便利なライブラリ。新しいフローとしては:
情報の処理・保存用のエクセル→→(コピー and Python実行)→→ブラウザに入力完了
となり、少しだけ作業工程を減らすことができる。なお、"Python実行" のところでは pyperclip で情報を取得して、selenium で入力という流れ。
準備としては、まずはインストール。
pip install pyperclip
コピー(Ctrl+C、Cmd+C、右クリックからコピー)してクリップボードにある文字列を取得するには:
import pyperclip
pyperclip.paste()
でOK。例えば、エクセルで縦に1から4まで入力して、その範囲をコピーしてからpyperclip.pate()を使ってみる:
print(pyperclip.paste())
# 1
# 2
# 3
# 4
Windows なら改行は "\r\n" なので分割してリスト化もできる:
print(pyperclip.paste().split("\r\n"))
# ['1', '2', '3', '4', '']
最後の空が気になるので、シンプルに:
print(pyperclip.paste().split())
# ['1', '2', '3', '4']
のが簡単。
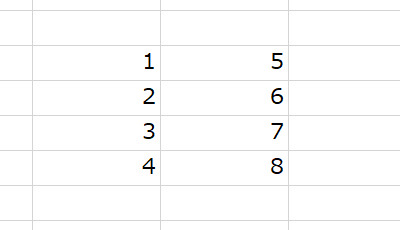
1列なら単に .split() でリスト化できるけれども、2列だと少し工夫(?)が必要。
エクセル上で1と5が横に並んでいるのは、"1\t5" というように、タブで区切られている。改行は上と同じ。なので、横に見て [[1,5],[2,6]...]というリストが欲しければ、まずは改行("\r\n")で区切り、それからタブ("\t")で区切ってあげれば良い:
print([i.split("\t") for i in pyperclip.paste().split("\r\n")])
# [['1', '5'], ['2', '6'], ['3', '7'], ['4', '8'], ['']]
やっぱり最後は空になってしまうので、if ではじいてあげる:
print([i.split("\t") for i in pyperclip.paste().split("\r\n") if len(i)>1])
# [['1', '5'], ['2', '6'], ['3', '7'], ['4', '8']]
pyperclipを使えば、一列のデータでも、2列(以上)のデータでも、コピーができるデータであれば簡単に取得して、リスト化ができると分かった。後は selenium に頑張ってもらってチクチク入力すれば完了。