前回の記事では、hist() を使って描いたヒストグラムに、各階級の度数を書き入れました。
ただ、毎回スクリプトを書いているのは面倒なので(?)、上記機能を組み入れたりして hist() を拡張した myhist() を作りました。
基本的には自分用なので、平均点を表す線を引いたりするのも入れてあります。もしもお役に立ちそうでしたらご自由にお使いください。
前回の記事では、hist() を使って描いたヒストグラムに、各階級の度数を書き入れました。
ただ、毎回スクリプトを書いているのは面倒なので(?)、上記機能を組み入れたりして hist() を拡張した myhist() を作りました。
基本的には自分用なので、平均点を表す線を引いたりするのも入れてあります。もしもお役に立ちそうでしたらご自由にお使いください。
やりたいこと:
R で hist() を使って、ヒストグラムを描き、つまり、次のような感じ:
加えて、各階級の度数を表示する。

ですので、
- $counts が度数
- $mids が階級値 (階級の真ん中の値)



与えられた英文を、各単語に分けてabc順に並べ替えスラッシュで区切る関数を、Rで書いたことがあった。例えば、
計9行。forが1つ。自分で使う分には一切問題がないし、頑張って書いたのでずっと使っていたのだが、ごちゃごちゃしている。書き直してみる。
計6行。forはないし、見た目もスッキリ。
以前はウンウン唸りながら1~2時間くらいかけて書いたものが、今では3分くらいで書けるように。私はR (を始めプログラミング) の専門的な訓練を受けたことはないが、本やインターネットのおかげで、自分にとって十分役にたつスクリプトが書けるようになってきた。このエントリーも誰かの役に立てば嬉しい。
なお、使い方は:



概要
"StrAlt" の"Tihs is an" を選択すると、単語の文字をバラバラ (かつ、元の形がなんとなくわかるよう) に並び替えます:
使い方

留意点
その他
Shiny を利用した他のウェブ・アプリもぜひお試しください:
デジタル一眼レフでは、JPGデータだけでなくRAWデータも記録できます。そのデータをパソコンに移すと、.JPG と .CR2 (こちらがRAWデータ) の2種類の拡張子を持つデータが保存されます。
.JPGのデータのみを別のフォルダ (Dropboxに作成したフォルダ) にコピーするスクリプトです:
.JPGで十分であればそのまま、不十分であればRAWデータを現像して上書き、という手順が便利です。
英文を単語に分解し、アルファベット順に並べ替え、さらに、並べ替えた後にア.イ.ウ. ... と記号をふるウェブ・アプリです。
たとえば、this is an example sentence と入力すると、
自動で、ア. an イ. example ウ. is エ. sentence オ. this と変換します。

使い方
その他
Shiny を利用した他のウェブ・アプリもぜひお試しください:
Rは、パッケージをダウンロード・インストールして関数を追加していくことができる。
Rをインストールしてから、install.packages() でダウンロードするパッケージのメモ。:
irtoys
ggplot2
koRpus
psych
RCurl
shiny
気がつき次第、追加していく。
概要
"StrAlt" は文字列を加工するウェブ・アプリです:
使い方

留意点
その他
Shiny を利用した他のウェブ・アプリもぜひお試しください:
TreeTagger を R で利用するためのラッパーである koRpus を使って、英語テキストの原形と品詞情報を得ます。なお、Mac (Yosemite) を使っています。
[1] TreeTagger と koRpus をダウンロード・インストールします:
[2] R を起動し、まずは下準備:
library(koRpus)
set.kRp.env(TT.cmd="/Users/[ユーザー名]/Applications/TreeTagger/cmd/tteng", lang="en")
set.kRp.env(TT.cmd=file.choose(), lang="en")とすると簡単。ファインダー (?) が立ち上がるので、cmdの下にあるtree-tagger-englishを選択。これで準備が完了です。
[3] 実際に分析をするには、分析したいファイルがある作業ディレクトリに移動してから:
taggedText(treetag("分析したいファイル名.txt"))でO.K.です。データフレームで返ってきます。
ggplot2 を使ってヒストグラムを描く。基本的な使い方のメモ。「3. まとめ」に一覧をリストアップしています。
data <- c( 0, 14, 30, 30, 46, 48, 49, 50, 52, 53, 54, 55, 56, 60, 63, 64, 65, 66, 68, 68, 72, 73, 74, 76, 78, 81, 81, 84, 86, 93, 93, 100 )を利用する (乱数をつかって作成した)。データフレームに変換する (列名は score とする):
data <- data.frame(score = data)
library(ggplot2)変数dataに入っているデータフレームの、列名score のデータを利用する、と考えると分かりやすい。わざわざ aes(x = data$score) とせずに aes(x = score) だけで良い様子。
m <- ggplot(data, aes(x = score))
m + geom_histogram()

m + geom_histogram(binwidth=10)
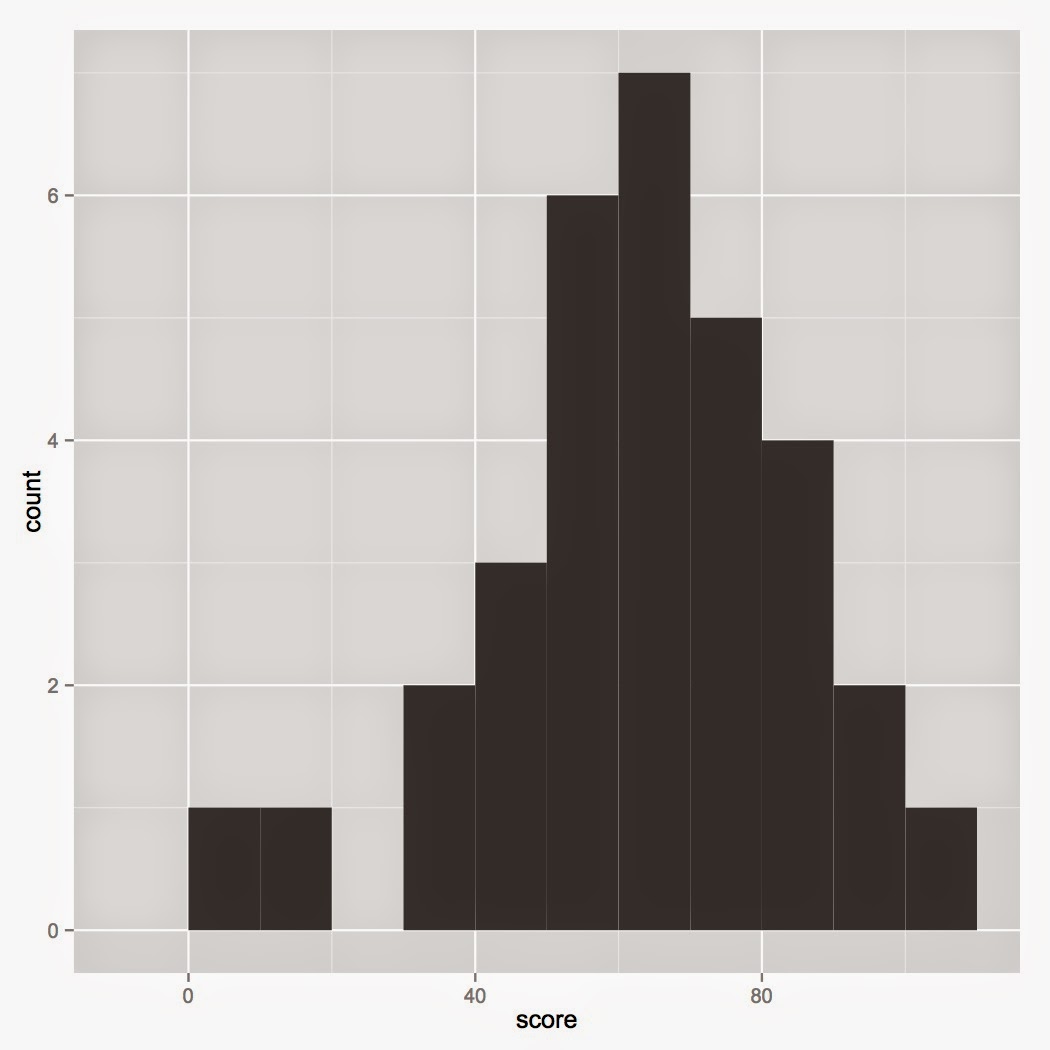
m + geom_histogram(binwidth=10, colour="black", fill=NA)

m + geom_histogram(binwidth= 10, colour="darkgreen", fill="skyblue")

0点より左側にビンが無く、100よりも右側にビンがあるのだ。ということから、binwidth=10 とした時、0~9, 10~19, 20~29,...,90~99, 100~109 という階級になっていることが分かる。
m + geom_histogram(breaks=seq(-0.5, 109.5, by=10), colour="darkgreen", fill="skyblue")

m + geom_histogram(binwidth=10, colour="black", fill=NA) + theme_bw()

m + geom_histogram(breaks=seq(-0.5, 109.5, by=10), colour="darkgreen", fill="skyblue") + theme_bw() + labs(y="Frequency", x="Score", title="Histogram of DATA")

m + geom_histogram(breaks=seq(-0.5, 109.5, by=10), colour="darkgreen", fill="skyblue") + ylim(0,10)

m + geom_histogram(binwidth=10, colour="darkgreen", fill="white") + coord_flip()

- データの指定: ggplot(変数名, aes(x = 列名))
- ヒストグラム描出: + geom_histogram()
- 幅を指定: + geom_histogram(binwidth = 数値)
- 枠線の色: + geom_histogram(colour = "色")
- ビンの色: + geom_histogram(fill = "色")
- 背景色を透明: + geom_histogram() + theme_bw()
- 軸やタイトル: + geom_histogram() + labs(x = "x軸名", y = "y軸名", title = "タイトル")
- 定義域の指定: + geom_histogram() + xlim( , )
- 値域の指定: + geom_histogram() + ylim( , )
- 図を横に倒す: + geom_histogram() + coord_flip()
調べ物をしていたら、ggplot2 を利用した図を何度か目にした。非常に美しい。ぜひ使えるようになりたい。以下、リンク:
上記リンク先の説明は、どれも非常に分かりやすい。図であろうと言語であろうと、情報を分かりやすく伝達するための配慮を感じる。
R でファイルパスを取得するためのメモ:
list.files()を利用する。lapply()と組み合わせると便利。
関連エントリーエクセル・データをコピペすると、ベクトル (x <- c(1,2,3) ) に変換するウェブ・アプリです。
背景
エクセル (Excel) でデータを管理し、分析の際に R を利用することがあります。そのために、エクセルのデータをCSVデータに変換し、Rで読み込む必要がありますが、その作業が面倒です。また慣れるまではとても難しく感じます (R を使い始めたばかりの頃、その作業が出来ず、手打ちでデータを読み込ませていました)。よし分析するぞ、と意気込んだものの、データの読み込みが出来ずがっかりする、という経験をした人は少なくないと思います。そこで、エクセルデータを単にコピー&ペーストするだけで、R で扱えるデータに変換してくれるウェブ・アプリを作りました。
使い方



上手な使い方
留意点
英文を単語に分解し、アルファベット順に並べ替え、さらに、並べ替えた後に番号をふるウェブ・アプリを作りました。
例えば、this is an example sentence と入力すると、
自動で ① an ② example ③ is ④ sentence ⑤ this と変換します。

使い方
英文を単語に分解し、アルファベット順に並べ替えるウェブ・アプリを作りました。
例えば、this is an example sentence と入力すると、
自動で ( an / example / is / sentence / this ) と変換します。

使い方
以前のエントリーの続き:
koRpus: an R packge for text analysis をインストールした:
install.packages("koRpus")
library(koRpus)
次は、実際に分析します:
参考x <- read.csv("file.csv", fileEncoding="cp932")
ソース
Shiny パッケージを使うと、インタラクティブな Web Application を手軽に作ることが出来るらしい。実物も拝見したが、とても素敵。
Rを使って、英語で書かれたテキストを分析する準備。便利なリンク先とメモ:
#tmパッケージをインストールする:
> install.packages("tm", dependencies=TRUE)
#tmパッケージを読み込む:
> library(tm)
